4. NV4(Fahrenheit) 마이크로아키텍처
5. NV10(Celsius) 마이크로아키텍처
7. NV30(Rankine) 마이크로아키텍처
NVIDIA의 데스크톱용
GPU를 기록한 문서.
OEM 전용 칩셋에는 *를 표시하거나 출시가에 -를 표시한다.2. 초대 마이크로아키텍처[편집]

NV1의 블록 다이어그램
| 프로세서별 최대 내부 구성 요소 |
프로세서
이름 | 공정
(㎚) | 면적
(㎟) | QDS | RZ | PP | 픽셀
INT32
ALU | TMU | ROP | MC
(bit)
(채널) |
| NV1 |
| NV1 | 500 | 90 | 1 | 1 | 1 | 4 | 1 | 1 | 32×2 |
| 프로세서별 특성 |
프로세서
이름 | 그래픽
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| NV1 |
| NV1 | DirectX 1.0
(S/W 가속)
자체 그래픽 API | - | PCI | FPM DRAM
EDO DRAM | VGA
(D-Sub) |
- QDS: Quadrangle Setup
- RZ: Rasterizer
- PP: Pixel Pipeline
- INT32: 32-bit Integer
- TMU: Texture Mapping Unit
- ROP: Raster Operation 또는 Render Output
- MC: Memory Controller
원래 NVIDIA의 2번째 그래픽카드가 될 예정이었으나 세상에 빛을 보지 못한 물건.
세가 새턴 후속기에 장착될 예정이었지만 하위 호환 기능이 제거되면서
드림캐스트에는
PowerVR 칩이 들어가게 되었다.
3. NV3 마이크로아키텍처[편집]

RIVA 128에 사용된 NV3의 전체 블록 다이어그램

RIVA 128에 사용된 NV3의 그래픽 엔진 부분 블록 다이어그램
| 프로세서별 최대 내부 구성 요소 |
프로세서
이름 | 공정
(㎚) | 면적
(㎟) | TRS | RZ | PP | 픽셀
INT32
ALU | TMU | 버텍스
캐시
(KB) | 텍스처
캐시
(KB) | Z
캐시
(KB) | 픽셀
캐시
(KB) | ROP | MC
(bit)
(채널) |
| NV3 |
| NV3 | 350 | 90 | 1 | 1 | 1 | 4 | 1 | ? | ? | ? | ? | 1 | 32×4 |
| 프로세서별 특성 |
프로세서
이름 | 그래픽
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| NV3 |
| NV3 | DirectX 5.0
OpenGL 1.1 | MPEG-2
Motion
Compensation | AGP 1×
PCI | SDR | VGA
(D-Sub) |
4. NV4(Fahrenheit) 마이크로아키텍처[편집]
| 프로세서별 최대 내부 구성 요소 |
프로세서
이름 | 공정
(㎚) | 면적
(㎟) | TRS | RZ | PP | 픽셀
INT32
ALU | TMU | 버텍스
캐시
(KB) | 텍스처
캐시
(KB) | Z
캐시
(KB) | 픽셀
캐시
(KB) | ROP | MC
(bit)
(채널) |
| NV4 |
| NV4 | 350 | 90 | 1 | 1 | 2 | 8 | 2 | ? | ? | ? | ? | 2 | 32×4 |
| NV5 | 250 | 90 | 1 | 1 | 2 | 8 | 2 | ? | ? | ? | ? | 2 | 32×4 |
| NV6 | 220 | 90 | 1 | 1 | 2 | 8 | 2 | ? | ? | ? | ? | 2 | 32×4 |
| 프로세서별 특성 |
프로세서
이름 | 그래픽
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| NV4 |
| NV4 | DirectX 6.0
OpenGL 1.2 | MPEG-2
Motion
Compensation | AGP 2×
PCI | SDR | VGA
(D-Sub) |
| NV5 | AGP 4×
AGP 2×
PCI |
| NV6 |
5. NV10(Celsius) 마이크로아키텍처[편집]

지포스 2 GTS에 사용된 NV15의 블록 다이어그램

지포스 2 MX에 사용된 NV11의 블록 다이어그램
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | T&L | 버텍스
FP32
벡터 | TRS | NSR | PP | 픽셀
INT32
ALU | TMU | 버텍스
캐시
(KB) | 텍스처
캐시
(KB) | Z
캐시
(KB) | 픽셀
캐시
(KB) | ROP | MC
(bit)
(채널) |
| NV10 |
| NV10 | 220 | 111 | 1 | 4 | 1 | 1 | 4 | 16 | 4 | ? | ? | ? | ? | 4 | 32×4 |
| NV11 | 180 | 65 | 1 | 4 | 1 | 1 | 2 | 8 | 4 | ? | ? | ? | ? | 2 | 32×4 |
| NV15 | 180 | 90 | 1 | 4 | 1 | 1 | 4 | 16 | 8 | ? | ? | ? | ? | 4 | 32×4 |
| NV16 | 150 | 81 | 1 | 4 | 1 | 1 | 4 | 16 | 8 | ? | ? | ? | ? | 4 | 32×4 |
| NV17 | 150 | 65 | 1 | 4 | 1 | 1 | 2 | 8 | 4 | ? | ? | ? | ? | 2 | 32×4 |
| NV18 | 150 | 65 | 1 | 4 | 1 | 1 | 2 | 8 | 4 | ? | ? | ? | ? | 2 | 32×4 |
| NV19 | 150 | 65 | 1 | 4 | 1 | 1 | 2 | 8 | 4 | ? | ? | ? | ? | 2 | 32×4 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| NV10 |
| NV10 | DirectX 7.0
OpenGL 1.2 | MPEG-2
Motion
Compensation | AGP 4× | SDR
DDR | VGA
(D-Sub)
DVI |
| NV11 | HDVP | AGP 4×
PCI |
| NV15 | AGP 4× |
| NV16 |
| NV17 | VPE |
| NV18 | AGP 8× |
| NV19 | PCIe ×16 |
- T&L: Transform & Lighting
- FP32: 32-bit(Single-Precision) Floating-Point Real Number
- NSR: NVIDIA Shading Rasterizer
GeForce라는 브랜드의 기원이 된 마이크로아키텍처의 시작이자 하드웨어 T&L을 지원하는 최초의 마이크로아키텍처.
6. NV20(Kelvin) 마이크로아키텍처[편집]

지포스 3 시리즈에 사용된 NV20의 버텍스 셰이더 블록 다이어그램

지포스 3 시리즈에 사용된 NV20의 버텍스 프로세스 블록 다이어그램

지포스 3 시리즈에 사용된 NV20의 픽셀 셰이더 블록 다이어그램

지포스 4 Ti 시리즈에 사용된 NV25의 블록 다이어그램
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | T&L | PVSP | 버텍스
셰이더
FP32
벡터 | TRS | RZ | PPSP | 픽셀
셰이더
INT32
ALU | TMU | 버텍스
캐시
(KB) | 텍스처
캐시
(KB) | Z
캐시
(KB) | 픽셀
캐시
(KB) | ROP | MC
(bit)
(채널) |
| NV20 |
| NV20 | 150 | 128 | 1 | 1 | 4 | 1 | 1 | 4 | 16 | 8 | ? | ? | ? | ? | 4 | 32×4 |
| NV25 | 150 | 142 | 1 | 2 | 8 | 1 | 1 | 4 | 16 | 8 | ? | ? | ? | ? | 4 | 32×4 |
| NV28 | 150 | 101 | 1 | 2 | 8 | 1 | 1 | 4 | 16 | 8 | ? | ? | ? | ? | 4 | 32×4 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| NV20 |
| NV20 | DirectX 8.0
OpenGL 1.3 | HDVP | AGP 4× | DDR | VGA
(D-Sub)
DVI |
| NV25 | SDR
DDR |
| NV28 | AGP 8× |
- PVSP: Programmable Vertex Shading Pipeline
- PPSP: Programmable Pixel Shading Pipeline
7. NV30(Rankine) 마이크로아키텍처[편집]

지포스 FX 5800 시리즈에 사용된 NV30의 블록 다이어그램
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | T&L | PVSP | 버텍스
셰이더
FP32
벡터 | TRS | RZ | PPSP | 픽셀
셰이더
FP32
ALU | 픽셀
셰이더
미니
ALU | TMU | 텍스처
컬러
보간기 | 지오메트리
텍스처
캐시
(KB) | 컬러
Z-타일
캐시
(KB) | ROP | MC
(bit)
(채널) |
| NV30 |
| NV30 | 130 | 200 | 1 | 3 | 12 | 1 | 1 | 8 | 32 | - | 8 | 8 | ? | ? | 8 | 32×4 |
| NV31 | 130 | 135 | 1 | 1 | 4 | 1 | 1 | 4 | 16 | - | 4 | 4 | ? | ? | 4 | 32×4 |
| NV34 | 150 | 91 | 1 | 1 | 4 | 1 | 1 | 4 | 16 | - | 4 | 4 | ? | ? | 4 | 32×4 |
| NV35 | 130 | 207 | 1 | 3 | 12 | 1 | 1 | 8 | 32 | 8 | 8 | 8 | ? | ? | 8 | 64×4 |
| NV36 | 130 | 125 | 1 | 3 | 12 | 1 | 1 | 4 | 16 | 4 | 4 | 4 | ? | ? | 4 | 32×4 |
| NV37 | 150 | 91 | 1 | 1 | 4 | 1 | 1 | 4 | 16 | - | 4 | 4 | ? | ? | 4 | 32×4 |
| NV38 | 130 | 207 | 1 | 3 | 12 | 1 | 1 | 8 | 32 | 8 | 8 | 8 | ? | ? | 8 | 64×4 |
| NV39 | 130 | 125 | 1 | 3 | 12 | 1 | 1 | 4 | 16 | 4 | 4 | 4 | ? | ? | 4 | 32×4 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| NV30 |
| NV30 | DirectX 9.0a
OpenGL 1.5
(H/W 1.5, S/W 2.1) | VPE | AGP 8× | DDR
GDDR2 | VGA
(D-Sub)
DVI |
| NV31 | DDR |
| NV34 |
| NV35 |
| NV36 | DDR
GDDR2 |
| NV37 | PCIe ×16 | DDR |
| NV38 | AGP 8× | DDR
GDDR3 |
| NV39 | PCIe ×16 | DDR |
여러가지 의미로 NVIDIA 첫 번째 삽질의 전설로 남은 기념비적 마이크로아키텍처... 얼마가지 않아 공정이 바뀌었다.
2008년 5월 13일에 175 버전이 마지막으로서 드라이버 공식 지원이 중단되었다. (단, Windows XP 호환 드라이버) DirectX 9.0과 셰이더 모델 2.0+를 지원하여 WDDM에 대응된 가장 오래된 시리즈이지만, 정작 Windows Vista 호환 드라이버는 2006년 10월 17일에 ForceWare 95 버전에 한 번 더 지원해주었다(...).
8. NV40(Curie) 마이크로아키텍처[편집]

지포스 6800 Ultra에 사용된 NV40의 블록 다이어그램.
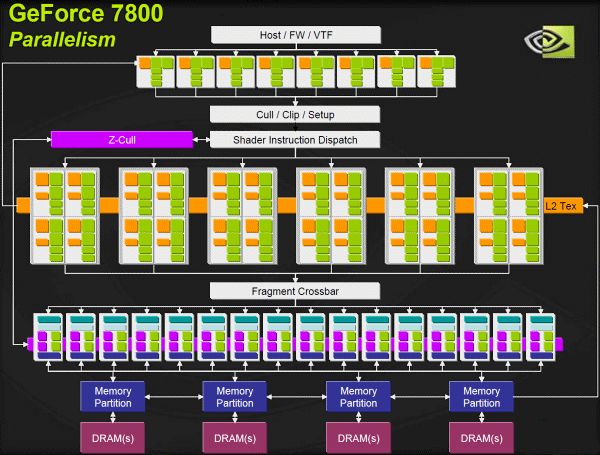
지포스 7800 GTX에 사용된 G70의 블록 다이어그램.
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | T&L | PVSP | 버텍스
셰이더
FP32
스칼라 | 버텍스
셰이더
FP32
벡터 | TRS | RZ | PPSP | 픽셀
셰이더
FP32
ALU | 픽셀
셰이더
미니
ALU | TMU | L1
텍스처
캐시
(KB) | L2
텍스처
캐시
(KB) | ROP | MC
(bit)
(채널) |
| NV40 |
| NV40 | 130 | 287 | 1 | 6 | 6 | 24 | 1 | 1 | 16 | 64×2 | 4×2 | 16 | ?×4 | ? | 16 | 64×4 |
| NV41 | 130 | 225 | 1 | 5 | 5 | 20 | 1 | 1 | 12 | 48×2 | 3×2 | 12 | ?×3 | ? | 12 | 64×4 |
| NV42 | 110 | 225 | 1 | 5 | 5 | 20 | 1 | 1 | 12 | 48×2 | 3×2 | 12 | ?×3 | ? | 12 | 64×4 |
| NV43 | 110 | 150 | 1 | 3 | 3 | 12 | 1 | 1 | 8 | 32×2 | 2×2 | 8 | ?×2 | ? | 4 | 64×2 |
| NV44 | 110 | 110 | 1 | 3 | 3 | 12 | 1 | 1 | 4 | 16×2 | 1×2 | 4 | ?×1 | ? | 2 | 32×2 |
| NV45 | 130 | 287 | 1 | 6 | 6 | 24 | 1 | 1 | 16 | 64×2 | 4×2 | 16 | ?×4 | ? | 16 | 64×4 |
| NV48 | 110 | 287 | 1 | 6 | 6 | 24 | 1 | 1 | 16 | 64×2 | 4×2 | 16 | ?×4 | ? | 16 | 64×4 |
| G70 |
| G70 | 110 | 333 | 1 | 8 | 8 | 32 | 1 | 1 | 24 | 96×2 | 6×2 | 24 | ?×6 | ? | 16 | 64×4 |
| G71 | 90 | 196 | 1 | 8 | 8 | 32 | 1 | 1 | 24 | 96×2 | 6×2 | 24 | ?×6 | ? | 16 | 64×4 |
| G72 | 90 | 81 | 1 | 3 | 3 | 12 | 1 | 1 | 4 | 16×2 | 1×2 | 4 | ?×1 | ? | 2 | 32×2 |
| G73 | 90 | 125 | 1 | 5 | 5 | 20 | 1 | 1 | 12 | 48×2 | 3×2 | 12 | ?×3 | ? | 8 | 64×2 |
| G73B | 80 | 100 | 1 | 5 | 5 | 20 | 1 | 1 | 12 | 48×2 | 3×2 | 12 | ?×3 | ? | 8 | 64×2 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| NV40 |
| NV40 | DirectX 9.0c
OpenGL 2.1 | VPE | AGP 8× | DDR
DDR2
GDDR3 | VGA
(D-Sub)
DVI |
| NV41 | PCIe ×16 | DDR
GDDR3 |
| NV42 | AGP 8× | GDDR3 |
| NV43 | PureVideo HD 1
(VDPAU 없음) | AGP 8×
PCIe ×16 | DDR
DDR2
GDDR3 |
| NV44 | AGP 8×
PCIe ×16 | DDR
DDR2 |
| NV45 | VPE | PCIe ×16 | GDDR3 |
| NV48 | AGP 8× | DDR
GDDR3 |
| G70 |
| G70 | DirectX 9.0c
OpenGL 2.1 | PureVideo HD 1
(VDPAU 없음) | AGP 8×
PCIe ×16 | DDR2
GDDR3 | VGA
(D-Sub)
DVI |
| G71 |
| G72 | DDR2 |
| G73 | DDR2
GDDR3 |
| G73B |
2015년 2월 24일에 309.08 버전이 마지막으로서 NV40 마이크로아키텍처 기반 모든 모델들의 드라이버 공식 지원이 중단되었다.
9. G80(Tesla) 마이크로아키텍처[편집]

은(는) 여기로 연결됩니다.
Tesla 제품군에 대한 내용은
NVIDIA/워크스테이션 GPU 문서
를
, {{{#!html }}}에 대한 내용은
문서
를
, {{{#!html }}}에 대한 내용은
문서
를
, {{{#!html }}}에 대한 내용은
문서
를
, {{{#!html }}}에 대한 내용은
문서
를
, {{{#!html }}}에 대한 내용은
문서
를
, {{{#!html }}}에 대한 내용은
문서
를
, {{{#!html }}}에 대한 내용은
문서
를
, {{{#!html }}}에 대한 내용은
문서
를
, {{{#!html }}}에 대한 내용은
문서
를
참고하십시오.


G80의 블록 다이어그램

G84의 블록 다이어그램

G200(GT200)의 블록 다이어그램
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | T&L | TRS | RZ | TPC | SM | CUDA
코어
(SP)
(FP32)
(INT32) | FP64 | SFU | TMU | L1
공유
캐시
(KB) | L1
텍스처
캐시
(KB) | L2
캐시
(KB) | ROP | MC
(bit)
(채널) |
| G80 |
| G80 | 90 | 484 | 1 | 1 | 1 | 8 | 16 | 128 | - | 32 | 32 | 8×16 | 16×8 | 128 | 24 | 64×6 |
| G84 | 80 | 169 | 1 | 1 | 1 | 2 | 4 | 32 | - | 8 | 16 | 8×4 | 16×2 | 32 | 8 | 64×2 |
| G86 | 80 | 127 | 1 | 1 | 1 | 1 | 2 | 16 | - | 4 | 8 | 8×2 | 16×1 | 16 | 4 | 64×2 |
| G92 | 65 | 324 | 1 | 1 | 1 | 8 | 16 | 128 | - | 32 | 64 | 8×16 | 16×8 | 64 | 16 | 64×4 |
| G94 | 65 | 240 | 1 | 1 | 1 | 4 | 8 | 64 | - | 16 | 32 | 8×8 | 16×4 | 64 | 16 | 64×4 |
| G96 | 65 | 144 | 1 | 1 | 1 | 2 | 4 | 32 | - | 8 | 16 | 8×4 | 16×2 | 32 | 8 | 64×2 |
| G98 | 65 | 86 | 1 | 1 | 1 | 1 | 1 | 8 | - | 2 | 8 | 8×2 | 16×1 | 16 | 4 | 64×1 |
| G92B | 55 | 260 | 1 | 1 | 1 | 8 | 16 | 128 | - | 32 | 64 | 8×16 | 16×8 | 64 | 16 | 64×4 |
| G94B | 55 | 196 | 1 | 1 | 1 | 4 | 8 | 64 | - | 16 | 32 | 8×8 | 16×4 | 64 | 16 | 64×4 |
| G96C | 55 | 121 | 1 | 1 | 1 | 2 | 4 | 32 | - | 8 | 16 | 8×4 | 16×2 | 32 | 8 | 64×2 |
| GT200 |
| G200 | 65 | 576 | 1 | 1 | 1 | 10 | 30 | 240 | 30 | 60 | 80 | 16×30 | 24×10 | 256 | 32 | 64×8 |
| G200B | 55 | 470 | 1 | 1 | 1 | 10 | 30 | 240 | 30 | 60 | 80 | 16×30 | 24×10 | 256 | 32 | 64×8 |
| GT215 | 40 | 144 | 1 | 1 | 1 | 4 | 12 | 96 | - | 24 | 32 | 8×12 | 16×4 | 64 | 8 | 64×2 |
| GT216 | 40 | 100 | 1 | 1 | 1 | 2 | 6 | 48 | - | 12 | 16 | 8×6 | 16×2 | 64 | 8 | 64×2 |
| GT218 | 40 | 57 | 1 | 1 | 1 | 1 | 2 | 16 | - | 4 | 8 | 8×2 | 16×1 | 32 | 4 | 64×1 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| G80 |
| G80 | DirectX 10.0
(FEATURE_LEVEL_10_0)
OpenGL 3.3 | CUDA Compute Capability 1.0
OpenCL 1.1 | PureVideo HD 1
(VDPAU 없음) | PCIe 1.1 ×16 | GDDR3 | VGA
(D-Sub)
DVI
(Dual Link) |
| G84 | CUDA Compute Capability 1.1
OpenCL 1.1 | PureVideo HD 2
(VDPAU Feature Set A) | DDR2
GDDR3 |
| G86 |
| G92 |
| G92 | DirectX 10.0
(FEATURE_LEVEL_10_0)
OpenGL 3.3 | CUDA Compute Capability 1.1
OpenCL 1.1 | PureVideo HD 2
(VDPAU Feature Set A) | PCIe 2.0 ×16 | GDDR3 | VGA
(D-Sub)
DVI
(Dual Link) |
| G92B | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.3 |
| G94 | DDR2
GDDR3 | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.3
DisplayPort 1.1 |
| G94B |
| G96 | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.3 |
| G96C |
| G98 | PureVideo HD 3
(VDPAU Feature Set B) |
| GT200 |
| G200 | DirectX 10.0
(FEATURE_LEVEL_10_0)
OpenGL 3.3 | CUDA Compute Capability 1.3
OpenCL 1.1 | PureVideo HD 2
(VDPAU Feature Set A) | PCIe 2.0 ×16 | GDDR3 | VGA
(D-Sub)
DVI
(Dual Link) |
| G200B | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.3 |
| GT215 | DirectX 10.1
(FEATURE_LEVEL_10_1)
OpenGL 3.3 | CUDA Compute Capability 1.2
OpenCL 1.1 | PureVideo HD 4
(VDPAU Feature Set C) | GDDR3
GDDR5 |
| GT216 | DDR2
GDDR3 |
| GT218 |
- TPC: Thread Processing Cluster (GPGPU 연산) 또는 Texture Processing Cluster (그래픽 연산)
- SM: Streaming Multiprocessor
- SP: Streaming Processor
- CUDA: Compute Unified Device Architecture
- FP64: 64-bit(Double-Precision) Floating-Point Real Number
- SFU: Special Function Unit
2016년 12월 14일에 342.01 버전이 마지막으로서 G80 마이크로아키텍처 기반 모든 모델들의 드라이버 공식 지원이 중단되었다.
그래픽 카드
모델명 | GPU | 그래픽 메모리 | GCP
(W) | 출고
가격
($) |
이름
(공정)
(면적) | CUDA:TMU:ROP
(T&L, RZ) | 클럭
(코어)
(셰이더)
(MHz) | L2
캐시
메모리
(KB) | 버스
(bit) | 규격 | 클럭
(비트레이트)
(MHz)
(Mbps) | 용량
(MB) |
| 데스크탑용 제품군 |
| GTS 150 | G92
(65㎚)
(324㎟) | 128:64:16
(1, 1) | 738
(1836) | 64 | 256 | GDDR3 | 1000
(2000) | 1024 | 141 | - |
| GT 140 | G94B
(55㎚)
(196㎟) | 64:32:16
(1, 1) | 650
(1625) | 900
(1800) | 105 | - |
| GT 130 | 48:24:12
(1, 1) | 500
(1250) | 48 | 192 | DDR2 | 500
(1000) | 512 | 75 | - |
| GT 120 | G96C
(55㎚)
(121㎟) | 32:16:8
(1, 1) | 738
(1836) | 32 | 128 | 504
(1008) | 50 | - |
| G 100 | G98
(65㎚)
(86㎟) | 8:8:4
(1, 1) | 540
(1300) | 16 | 64 | 400
(800) | 256 | 35 | - |
- 【이론적인 성능 계산식 펼치기 · 접기】
< 범용 연산 성능 >
(GPU 클럭) × (CUDA 코어의 개수) × 2 ÷ 1000 = (FP32 연산 속도) [GFLOPS]
(GPU 클럭) × (CUDA 코어의 개수) ÷ 1000 = (INT32 연산 속도) [GIPS]
< 특수 연산 성능 >
(GPU 클럭) × (T&L의 개수) ÷ 1000 = (삼각형 생성 개수) [GTriangles/s]
(GPU 클럭) × (RZ의 개수) × 8 ÷ 1000 = (래스터라이제이션) [GPixels/s]
(GPU 클럭) × (ROP의 개수) ÷ 1000 = (픽셀 필레이트) [GPixels/s]
(GPU 클럭) × (TMU의 개수) ÷ 1000 = (텍스처 필레이트) [GTexel/s]
< 그래픽 메모리 성능 >
(메모리 버스) ÷ 8 × (메모리 비트레이트) ÷ 1000 = (메모리 대역폭) [GB/s]
|
- 【용어 전체 이름 펼치기 · 접기】
Single-Precision Floating-Point = FP32
32-bit Integer = INT32
Compute Unified Device Architecture = CUDA
Texture Mapping Unit = TMU
Render Output Pipeline = ROP
Raster Engine = RE
Transform & Lighting = T&L
Thermal Design Power = TDP
Total Graphics Power = TGP
Graphics Card Power = GCP
Max Power Consumption = MPC
|
2009년 3월부터 출시된 7세대 마이크로아키텍처 개선판이자 9번째 지포스의
리네이밍 겸 OEM 전용 제품군.
지포스 200 시리즈 칩셋의 출시 이후인 2008년 후반에 기존 칩셋들도 지포스 200 시리즈와 같은 형식의 네이밍으로 변경될거라는 방침에 따라 기존에 8 시리즈 → 9 시리즈로 넘어갈 때에는 공정이라도 개선될 겸 네이밍을 변경했다면, 이번엔 공정 변경도 없이 네이밍만 100 시리즈로 변경되었다.
[1] 기존의 복잡한 네이밍 형식에서 벗어나려는 의도라고는 하지만, 그렇다고 시중에서 기존 모델의 네이밍이 새로운 형식으로 저절로 바뀌는게 아니기 때문에 사실상 더 복잡해진거나 다름 없었다.
뚜껑을 열고 보니 지포스 8 시리즈의 65nm 공정 개선판이 지포스 9 시리즈였다면, 이쪽은 지포스 9 시리즈의 55nm 공정 개선판...이 아니라 이미 55nm로 공정 개선된 지포스 9 시리즈 일부를 리네이밍시킨 것(...). OEM용으로만 출시해서 2009년 2분기 즈음부터 출시된 노트북이나 브랜드PC에 확인할 수 있었지만, OEM 전용 라인업이라 인지도가 바닥을 기어가고 있다(...).
그래픽 카드
모델명 | GPU | 그래픽 메모리 | GCP
(W) | 출고
가격
($) |
이름
(공정)
(면적) | CUDA:TMU:ROP
(T&L, RZ) | 클럭
(코어)
(셰이더)
(MHz) | L2
캐시
메모리
(KB) | 버스
(bit) | 규격 | 클럭
(비트레이트)
(MHz)
(Mbps) | 용량
(MB) |
| 데스크탑용 제품군 |
| GT 340 | GT215
(40㎚)
(144㎟) | 96:32:8
(1, 1) | 550
(1340) | 64 | 128 | GDDR5 | 850
(3400) | 1024 | 69 | - |
| GT 330 | GDDR3 | 1000
(2000) | 512 | 75 | - |
| GT 320 | 72:24:8
(1, 1) | 540
(1302) | 790
(1580) | 1024 | 43 | - |
| 315 | GT216
(40㎚)
(100㎟) | 48:16:8
(1, 1) | 475
(1100) | 32 | 64 | DDR2
DDR3 | 512 | 33 | - |
| 310 | GT218
(40㎚)
(57㎟) | 16:8:4
(1, 1) | 589
(1402) | 333
(666) | 31 | - |
- 【이론적인 성능 계산식 펼치기 · 접기】
< 범용 연산 성능 >
(GPU 클럭) × (CUDA 코어의 개수) × 2 ÷ 1000 = (FP32 연산 속도) [GFLOPS]
(GPU 클럭) × (CUDA 코어의 개수) ÷ 1000 = (INT32 연산 속도) [GIPS]
< 특수 연산 성능 >
(GPU 클럭) × (T&L의 개수) ÷ 1000 = (삼각형 생성 개수) [GTriangles/s]
(GPU 클럭) × (RZ의 개수) × 8 ÷ 1000 = (래스터라이제이션) [GPixels/s]
(GPU 클럭) × (ROP의 개수) ÷ 1000 = (픽셀 필레이트) [GPixels/s]
(GPU 클럭) × (TMU의 개수) ÷ 1000 = (텍스처 필레이트) [GTexel/s]
< 그래픽 메모리 성능 >
(메모리 버스) ÷ 8 × (메모리 비트레이트) ÷ 1000 = (메모리 대역폭) [GB/s]
|
- 【용어 전체 이름 펼치기 · 접기】
Single-Precision Floating-Point = FP32
32-bit Integer = INT32
Compute Unified Device Architecture = CUDA
Texture Mapping Unit = TMU
Render Output Pipeline = ROP
Raster Engine = RE
Transform & Lighting = T&L
Thermal Design Power = TDP
Total Graphics Power = TGP
Graphics Card Power = GCP
Max Power Consumption = MPC
|
2009년 11월 말부터 출시된 7.5세대 마이크로아키텍처이자 10번째 지포스의
리네이밍 겸 OEM 전용 제품군.
지포스 100 시리즈와 마찬가지로 OEM용으로 출하된 칩셋으로 시중에는 풀리지 않았고 삼성, HP등 브랜드 PC 제조업체의 제품에서만 접할 수 있는 제품군이며, 브랜드 PC 내부에 장착되어 있던 OEM용 그래픽카드가 따로 적출되어 중고로 판매되기도 했다.
GeForce 405(OEM, GT218), GeForce GT 415(OEM, GT216) 한정.


GF100의 블록 다이어그램.

GF100과 GF104의 블록 다이어그램 비교.
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | SM | PE | CUDA
코어
(FP32)
(INT32) | FP64 | SFU | TMU | L1
공유
캐시
(KB) | L1
텍스처
캐시
(KB) | L2
캐시
(KB) | ROP | MC
(bit)
(채널) |
| Fermi |
| GF100 | 40 | 529 | 4 | 4 | 16 | 16 | 512 | - | 64 | 64 | 64×16 | 12×16 | 768 | 48 | 64×6 |
| GF104 | 40 | 332 | 2 | 2 | 8 | 8 | 384 | - | 64 | 64 | 64×8 | 12×8 | 512 | 32 | 64×4 |
| GF106 | 40 | 238 | 1 | 1 | 4 | 4 | 192 | - | 32 | 32 | 64×4 | 12×4 | 384 | 24 | 64×3 |
| GF108 | 40 | 116 | 1 | 1 | 2 | 2 | 96 | - | 16 | 16 | 64×2 | 12×2 | 128 | 4 | 64×2 |
| Fermi 2.0 |
| GF110 | 40 | 520 | 4 | 4 | 16 | 16 | 512 | - | 64 | 64 | 64×16 | 12×16 | 768 | 48 | 64×6 |
| GF114 | 40 | 332 | 2 | 2 | 8 | 8 | 384 | - | 64 | 64 | 64×8 | 12×8 | 512 | 32 | 64×4 |
| GF116 | 40 | 238 | 1 | 1 | 4 | 4 | 192 | - | 32 | 32 | 64×4 | 12×4 | 384 | 24 | 64×3 |
| GF117 | 40 | 116 | 1 | 1 | 2 | 2 | 96 | - | 16 | 16 | 64×2 | 12×2 | 128 | 4 | 64×2 |
| GF119 | 40 | 79 | 1 | 1 | 1 | 1 | 48 | - | 8 | 8 | 64×1 | 12×1 | 128 | 4 | 64×1 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| Fermi |
| GF100 | DirectX 12
(FEATURE_LEVEL_11_0)
OpenGL 4.6 | CUDA Compute Capability 2.0
OpenCL 1.1 | PureVideo HD 4
(VDPAU Feature Set C) | PCIe 2.0 ×16 | GDDR5 | DVI
(Dual Link)
HDMI 1.4
DisplayPort 1.1 |
| GF104 | CUDA Compute Capability 2.1
OpenCL 1.1 | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.4
DisplayPort 1.1 |
| GF106 | DDR3
GDDR5 |
| GF108 |
| Fermi 2.0 |
| GF110 | DirectX 12
(FEATURE_LEVEL_11_0)
OpenGL 4.6 | CUDA Compute Capability 2.0
OpenCL 1.1 | PureVideo HD 4
(VDPAU Feature Set C) | PCIe 2.0 ×16 | GDDR5 | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.4
DisplayPort 1.1 |
| GF114 | CUDA Compute Capability 2.1
OpenCL 1.1 |
| GF116 | DDR3
GDDR5 |
| GF117 | PureVideo HD 5
(VDPAU Feature Set D) | DDR3 | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.4 |
| GF119 |
여기서부터 마이크로아키텍처 이름에
과학자의 이름을 붙이며, 이전 마이크로아키텍처들도 소급 적용하게 되었지만 과거 모델을 직접 사용해본 경험이 있으면서 지식을 가지고 있는 사람이 아닌 한, 대부분 있는 줄도 모르는 정보인데다 잘 알고 있더라도 당시의 명칭에 익숙해져서 그다지 잘 알려지지 않았다. 결정적으로 너무 오래된 마이크로아키텍처들이라 잘 거론되지 않는 편. 따라서, 소급 적용된 명칭들을 괄호 내에 표시하고 당시의 명칭을 기준으로 서술한다.
배정밀도 부동소수점 연산을 맡았던 전용 유닛이 제거된 대신 GF100은 2개, GF104 이하들은 4개의 CUDA를 동원해서 수행하며, SFU는 부동소수점 곱셈을 수행하지 않으므로 이론적인 연산 성능의 계산에서 제외된다.
2018년 3월 27일에 391.35 버전이 마지막으로서 페르미 마이크로아키텍처 기반 모든 모델들의 드라이버 공식 지원이 중단되었다.
GeForce GT 610, GT 620, GT 630(GF108), GT 640(GF116), GT 730(GF108) 등 페르미 기반 모델 한정.

GK104의 블록 다이어그램.

GK110의 블록 다이어그램.
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | SMX | PE | CUDA
코어
(FP32)
(INT32) | FP64 | SFU | TMU | L1
공유
캐시
(KB) | L1
텍스처
캐시
(KB) | L2
캐시
(KB) | ROP | MC
(bit)
(채널) |
| Kepler |
| GK110 | 28 | 561 | 5 | 5 | 15 | 15 | 2880 | 960 | 480 | 240 | 64×15 | 48×15 | 1536 | 48 | 64×6 |
| GK104 | 28 | 294 | 4 | 4 | 8 | 8 | 1536 | 64 | 256 | 128 | 64×8 | 48×8 | 512 | 32 | 64×4 |
| GK106 | 28 | 221 | 3 | 3 | 5 | 5 | 960 | 40 | 160 | 80 | 64×5 | 48×5 | 384 | 24 | 64×3 |
| GK107 | 28 | 118 | 1 | 1 | 2 | 2 | 384 | 16 | 64 | 32 | 64×2 | 48×2 | 256 | 16 | 64×2 |
| Kepler 2.0 |
| GK208 | 28 | 87 | 1 | 1 | 2 | 2 | 384 | 16 | 64 | 32 | 64×2 | 48×2 | 512 | 8 | 64×1 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| Kepler |
| GK110 | DirectX 12
(FEATURE_LEVEL_11_0)
OpenGL 4.6
Vulkan 1.2 | CUDA Compute Capability 3.5
OpenCL 1.2 | PureVideo HD 5
(VDPAU Feature Set D)
NVDEC
NVENC | PCIe 3.0 ×16 | GDDR5 | DVI
(Dual Link)
HDMI 1.4a
DisplayPort 1.2 |
| GK104 | CUDA Compute Capability 3.0
OpenCL 1.2 |
| GK106 | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.4a
DisplayPort 1.2 |
| GK107 | DDR3
GDDR5 |
| Kepler 2.0 |
| GK208 | DirectX 12
(FEATURE_LEVEL_11_0)
OpenGL 4.6
Vulkan 1.2 | CUDA Compute Capability 3.5
OpenCL 1.2 | PureVideo HD 5
(VDPAU Feature Set D)
NVDEC
NVENC | PCIe 2.0 ×8 | DDR3
GDDR5 | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.4a
DisplayPort 1.2 |
2021년 8월 31일에 케플러 마이크로아키텍처 기반 모든 모델들의 윈도우 7, 8, 8.1용 게임 레디 드라이버 공식 지원이 중단되었다. 심각한 보안 문제 해결 업데이트는 2024년 9월까지 제공한다고 발표했다.

GM107의 블록 다이어그램.

GM204의 블록 다이어그램.
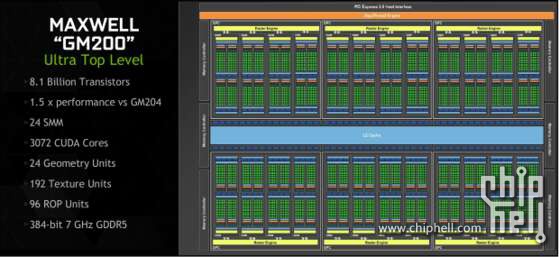
GM200의 블록 다이어그램.
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | SMM | PE | CUDA
코어
(FP32)
(INT32) | FP64 | SFU | TMU | L1
공유
캐시
(KB) | L1
텍스처
캐시
(KB) | L2
캐시
(MB) | ROP | MC
(bit)
(채널) |
| Maxwell |
| GM107 | 28 | 148 | 1 | 1 | 5 | 5 | 640 | 20 | 160 | 40 | 64×5 | 48×5 | 2 | 16 | 64×2 |
| GM108 | 28 | 81 | 1 | 1 | 3 | 3 | 384 | 12 | 96 | 24 | 64×3 | 48×3 | 1 | 8 | 64×1 |
| Maxwell 2.0 |
| GM200 | 28 | 601 | 6 | 6 | 24 | 24 | 3072 | 96 | 768 | 192 | 96×24 | 48×24 | 3 | 96 | 64×6 |
| GM204 | 28 | 398 | 4 | 4 | 16 | 16 | 2048 | 64 | 512 | 128 | 96×16 | 48×16 | 2 | 64 | 64×4 |
| GM206 | 28 | 228 | 2 | 2 | 8 | 8 | 1024 | 32 | 256 | 64 | 96×8 | 48×8 | 1 | 32 | 64×2 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| Maxwell |
| GM107 | DirectX 12
(FEATURE_LEVEL_11_0)
OpenGL 4.6
Vulkan 1.2 | CUDA Compute Capability 5.0
OpenCL 1.2 | PureVideo HD 6
(VDPAU Feature Set E)
NVDEC
NVENC | PCIe 3.0 ×16 | DDR3
GDDR5 | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 1.4a
DisplayPort 1.2 |
| GM108 | PureVideo HD 6
(VDPAU Feature Set E)
NVDEC
NVENC 미지원 | PCIe 3.0 ×4 |
| Maxwell 2.0 |
| GM200 | DirectX 12
(FEATURE_LEVEL_12_1)
OpenGL 4.6
Vulkan 1.2 | CUDA Compute Capability 5.2
OpenCL 1.2 | PureVideo HD 6
(VDPAU Feature Set E)
NVDEC 2
NVENC 5 | PCIe 3.0 ×16 | GDDR5 | DVI
(Dual Link)
HDMI 2.0
DisplayPort 1.2 |
| GM204 |
| GM206 | PureVideo HD 7
(VDPAU Feature Set F)
NVDEC 2
NVENC 5 |
GeForce GTX 750 Ti, GTX 750, GTX 745 한정.

GP100의 블록 다이어그램.

GP104의 블록 다이어그램.
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | TPC | PE | SM | CUDA
코어
(FP32)
(INT32) | FP64 | SFU | TMU | L1
공유
캐시
(KB) | L1
텍스처
캐시
(KB) | L2
캐시
(MB) | ROP | MC
(bit)
(채널) |
| Pascal |
| GP100 | 16 | 610 | 6 | 6 | 30 | 30 | 60 | 3840 | 1920 | 960 | 240 | 64×60 | 48×60 | 4 | 128 | 512×8 |
| GP102 | 16 | 471 | 6 | 6 | 30 | 30 | 30 | 3840 | 120 | 960 | 240 | 96×30 | 48×30 | 3 | 96 | 32×12 |
| GP104 | 16 | 314 | 4 | 4 | 20 | 20 | 20 | 2560 | 80 | 640 | 160 | 96×20 | 48×20 | 2 | 64 | 32×8 |
| GP106 | 16 | 200 | 2 | 2 | 10 | 10 | 10 | 1280 | 40 | 320 | 80 | 96×10 | 48×10 | 1.5 | 48 | 32×6 |
| GP107 | 14 | 132 | 1 | 1 | 6 | 6 | 6 | 768 | 24 | 192 | 48 | 96×6 | 48×6 | 1 | 32 | 32×4 |
| GP108 | 14 | 74 | 1 | 1 | 3 | 3 | 3 | 384 | 12 | 96 | 24 | 96×3 | 48×3 | 0.5 | 16 | 32×2 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| Pascal |
| GP100 | DirectX 12
(FEATURE_LEVEL_12_1)
OpenGL 4.6
Vulkan 1.2 | CUDA Compute Capability 6.0
OpenCL 1.2 | PureVideo HD ?
(VDPAU Feature Set ?)
NVDEC ?
NVENC ? | PCIe 3.0 ×16 | HBM2 | DVI
(Dual Link)
DisplayPort 1.4 |
| GP102 | CUDA Compute Capability 6.1
OpenCL 1.2 | PureVideo HD 8
(VDPAU Feature Set G, H)
NVDEC 3
NVENC 6 | GDDR5X | DVI
(Dual Link)
HDMI 2.0b
DisplayPort 1.4 |
| GP104 | GDDR5
GDDR5X |
| GP106 | GDDR5 |
| GP107 |
| GP108 | PureVideo HD 8
(VDPAU Feature Set G, H)
NVDEC 3
NVENC 미지원 | PCIe 3.0 ×4 | DDR4
GDDR5 | VGA
(D-Sub)
DVI
(Dual Link)
HDMI 2.0b
DisplayPort 1.4 |
NVIDIA 공식 홈페이지에서 '지포스 1000 시리즈'가 아닌 \
'지포스 10 시리즈'로 표기되어 있다. 자세한 사항은
공식 홈페이지의 해당 시리즈 참고.

GV100의 블록 다이어그램.
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | TPC | PE | SM | FP32 | INT32 | FP64 | TC | SFU | TMU | L1
캐시
(KB) | L2
캐시
(MB) | ROP | MC
(bit)
(채널) |
| Volta |
| GV100 | 12 | 815 | 6 | 6 | 42 | 42 | 84 | 5376 | 5376 | 2688 | 672 | 1344 | 336 | 128×84 | 6 | 128 | 512×8 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| Volta |
| GV100 | DirectX 12
(FEATURE_LEVEL_12_1)
OpenGL 4.6
Vulkan 1.2 | CUDA Compute Capability 7.0
OpenCL 2.0 | PureVideo HD 9
(VDPAU Feature Set I)
NVDEC 3
NVENC 6 | PCIe 3.0 ×16 | HBM2 | HDMI 2.0b
DisplayPort 1.4 |

TU102의 블록 다이어그램.

TU104의 블록 다이어그램.

TU106의 블록 다이어그램.

TU116의 블록 다이어그램.

TU117의 블록 다이어그램.
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | TPC | PE | SM | RTC | FP32 | INT32 | FP64 | TC | FP16 | SFU | TMU | L1
캐시
(KB) | L2
캐시
(MB) | ROP | MC
(bit)
(채널) |
| Turing |
| TU102 | 12 | 754 | 6 | 6 | 36 | 36 | 72 | 72 | 4608 | 4608 | 144 | 576 | - | 1152 | 288 | 96×72 | 6 | 96 | 32×12 |
| TU104 | 12 | 545 | 6 | 6 | 24 | 24 | 48 | 48 | 3072 | 3072 | 96 | 384 | - | 768 | 192 | 96×48 | 4 | 64 | 32×8 |
| TU106 | 12 | 445 | 3 | 3 | 18 | 18 | 36 | 36 | 2304 | 2304 | 72 | 288 | - | 576 | 144 | 96×36 | 4 | 64 | 32×8 |
| TU116 | 12 | 284 | 3 | 3 | 12 | 12 | 24 | - | 1536 | 1536 | 48 | - | 3072 | 384 | 96 | 96×24 | 1.5 | 48 | 32×6 |
| TU117 | 12 | 200 | 2 | 2 | 8 | 8 | 16 | - | 1024 | 1024 | 32 | - | 2048 | 256 | 64 | 96×16 | 1 | 32 | 32×4 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| Turing |
| TU102 | DirectX 12
(FEATURE_LEVEL_12_2)
OpenGL 4.6
Vulkan 1.2 | CUDA Compute Capability 7.5
OpenCL 1.2 | PureVideo HD 10
(VDPAU Feature Set J)
NVDEC 4
NVENC 7 | PCIe 3.0 ×16
NVLink 2.0 | GDDR6 | HDMI 2.0b
DisplayPort 1.4a
USB Type-C |
| TU104 |
| TU106 | PCIe 3.0 ×16 | DVI
(Dual Link)
HDMI 2.0b
DisplayPort 1.4a
USB Type-C |
| TU116 | DirectX 12
(FEATURE_LEVEL_12_1)
OpenGL 4.6
Vulkan 1.2 | GDDR5
GDDR6 | DVI
(Dual Link)
HDMI 2.0b
DisplayPort 1.4a |
| TU117 | PureVideo HD 10
(VDPAU Feature Set J)
NVDEC 4
NVENC 6 |
2017년 GTC 유럽 NVIDIA CEO 젠슨 황의 오프닝 키노트에서 젠승 황은 세계 최초의 로봇 택시용 AI 컴퓨터인
페가수스(Pegasus)에 차세대 마이크로아키텍처 기반 GPU가 Volta 마이크로아키텍처 기반 임베디드 GPU를 탑재한 자비에(Xavier) SoC 프로세서와 함께 결합될 예정이라고 밝혔다. 당시에는 공식 명칭을 밝혀지지 않고, 단순히 차세대 마이크로아키텍처라고 불렀는데, 나중에 엔비디아의 공식 발표를 통해, 해당 아키텍처가 튜링임이 밝혀졌다.

GA100의 블록 다이어그램.

GA102의 블록 다이어그램.

GA104의 블록 다이어그램.

GA106의 블록 다이어그램.
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | TPC | PME | SM | RTC | FP32 | INT32 | FP64 | TC | SFU | TMU | L1
캐시
메모리
(KB) | ROP | L2
캐시
메모리
(MB) | MC
(bit)
(채널) |
| Ampere |
| GA100 | 7 | 826 | 8 | - | 64 | - | 128 | - | 8192 | 8192 | 4096 | 512 | 2048 | 512 | 192×128 | - | 48 | 512×12 |
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | TPC | PME | SM | RTC | FP32
전용
CUDA
코어 | CUDA
코어
(FP32)
(INT32) | FP64 | TC | SFU | TMU | L1
캐시
메모리
(KB) | ROP | L2
캐시
메모리
(MB) | MC
(bit)
(채널) |
| Ampere |
| GA102 | 8 | 628.4 | 7 | 7 | 42 | 42 | 84 | 84 | 5376 | 5376 | 168 | 336 | 1344 | 336 | 128×84 | 112 | 6 | 32×12 |
| GA103 | 8 | 496.0 | 6 | 6 | 30 | 30 | 60 | 60 | 3840 | 3840 | 120 | 240 | 960 | 240 | 128×60 | 96 | 5 | 32×10 |
| GA104 | 8 | 392.5 | 6 | 6 | 24 | 24 | 48 | 48 | 3072 | 3072 | 96 | 192 | 768 | 192 | 128×48 | 96 | 4 | 32×8 |
| GA106 | 8 | 276.0 | 3 | 3 | 15 | 15 | 30 | 30 | 1920 | 1920 | 60 | 120 | 480 | 120 | 128×30 | 48 | 2.25 | 32×6 |
| GA107 | 8 | ? | 2 | 2 | 10 | 10 | 20 | 20 | 1280 | 1280 | 40 | 80 | 320 | 80 | 128×20 | 32 | ? | 32×4 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| Ampere |
| GA100 | DirectX ?
(FEATURE_LEVEL_?_?)
OpenGL ?.?
Vulkan ?.? | CUDA Compute Capability 8.0
OpenCL 2.0 | PureVideo HD ?
(VDPAU Feature Set ?)
NVDEC ?
NVENC 미지원 | PCIe 4.0 ×16
NVLink 3.0 | HBM2
HBM2E | HDMI ?.?
DisplayPort ?.?
? |
| GA102 | DirectX 12
(FEATURE_LEVEL_12_2)
OpenGL 4.6
Vulkan 1.2 | CUDA Compute Capability 8.6
OpenCL 2.0 | PureVideo HD 11
(VDPAU Feature Set K)
NVDEC 5
NVENC 7 | GDDR6X | HDMI 2.1
DisplayPort 1.4a |
| GA103 | PCIe 4.0 ×16 | GDDR6
GDDR6X |
| GA104 |
| GA106 | GDDR6 |
| GA107 |
2019년경의 뉴스에 따르면, 차세대 아키텍처의 명칭이
Ampere가 될 것이라고 한다. 한때, 삼성이 이 제품의 생산을 전량 수주했다는 루머가 있었으나,
젠슨 황이 이를 직접 부인하고, 이전 세대와 마찬가지로
TSMC가 기본 생산 업체이고, 물량이 부족할 때 삼성이 생산을 거들 것이라 밝혔다.
(출처)2019년 3월 31일, 모 트위터 유저가 트윗한 내용에 따르면 GA100으로 추정되는 연산 특화용 Ampere 기반 GPU가 7nm 공정으로 테이프 아웃되었다고 한다.
(출처) 이전 세대와 비슷한 패턴일 경우 이변이 없다면 2020년 상반기에 출시될 가능성이 높으나,
코로나바이러스감염증-19라는 큰 이변이 발생해서 발표 일정이 지연될 확률이 높아졌다.
2020년 5월 14일, 다행히 GTC 2020이 온라인으로 진행되어서 발표 시기 자체는 크게 미루어지지 않았고, Ampere 마이크로아키텍처와 GA100이 공식 발표되었다. TSMC N7 공정이
[2] 1세대 7nm 공정인 N7인지, 2세대 7nm 공정인 N7P인지는 불명. TSMC가 7nm 계열 공정들을 다 똑같은 'N7' 명칭으로 취급하고 있기 때문에 정확한 공정을 확인할 수 없다.
사용되었고 다이 사이즈는 826 ㎟로 815 ㎟였던 GV100보다 조금 더 커졌지만, 트랜지스터는 무려 540억여개로 211억여개였던 GV100보다 2.5배 더 많은 개수를 지니고 있다. 그런 상태에서 GA100 컷칩이 사용된 A100의 GPU 클럭이 GV100 컷칩이 사용된 V100에 비해 그다지 향상되지 않은 점을 미루어 보면 TSMC가 내놓은 N7 공정 중에 고성능(HP) 버전이 아닌 고밀도(HD) 버전일 가능성이 높다.

GH100의 블록 다이어그램.
| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | TPC | PME | SM | RTC | FP32 | INT32 | FP64 | TC | SFU | TMU | L1
캐시
메모리
(KB) | ROP | L2
캐시
메모리
(MB) | MC
(bit)
(채널) |
| Hopper |
| GH100 | 4 | 814 | 8 | - | 72 | - | 144 | - | 18432 | 9216 | 9216 | 576 | 2304 | 576 | 256×144 | - | 60 | 512×12 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| Hopper |
| GH100 | - | CUDA Compute Capability 9.0
OpenCL ?.? | PureVideo HD ?
(VDPAU Feature Set ?)
NVDEC ?
NVENC 미지원 | PCIe 5.0 ×16
NVLink 4.0 | HBM2E
HBM3 | - |
2022년 3월 23일에 발표된 데이터센터 전용 GPU 마이크로아키텍처.
2015년부터 모바일 플랫폼의 미세 공정 노드가 데스크톱 및 워크스테이션 플랫폼의 미세 공정 노드를 추월하기 시작했고, 특히
Apple이 TSMC의 5 nm 공정 생산 용량의 거의 독점에 가까운 비중을 차지하고 있었기 때문에, Hopper의 공정 노드는 '잘해봐야 5 nm일 것'이 중론이었다. 다행히 TSMC N5 기반의 NVIDIA 커스텀 노드인 4N으로 밝혀졌다. 단, 진짜 4 nm인 N4와 다른 노드이므로 유의할 것.

| GPU별 최대 내부 구성 요소 |
GPU
이름 | 공정
(㎚) | 면적
(㎟) | GPC | RE | TPC | PME | SM | RTC | FP32
전용
CUDA
코어 | CUDA
코어
(FP32)
(INT32) | FP64 | TC | SFU | TMU | L1
캐시
메모리
(KB) | ROP | L2
캐시
메모리
(MB) | MC
(bit)
(채널) |
| Ada Lovelace |
| AD102 | 4 | 608.5 | 12 | 12 | 72 | 12 | 144 | 144 | 9216 | 9216 | 288 | 576 | 2304 | 576 | 128×144 | 192 | 96 | 32×12 |
| AD103 | 4 | 378.6 | 7 | 7 | 40 | 7 | 80 | 80 | 5120 | 5120 | 160 | 320 | 1280 | 320 | 128×80 | 112 | 64 | 32×8 |
| AD104 | 4 | 294.5 | 5 | 5 | 30 | 5 | 60 | 60 | 3840 | 3840 | 120 | 240 | 960 | 240 | 128×60 | 80 | 48 | 32×6 |
| GPU별 특성 |
GPU
이름 | 그래픽
가속 | GPGPU
가속 | 비디오
가속 | 호스트
인터페이스 | 메모리
규격 | 디스플레이
출력 |
| Ada Lovelace |
| AD102 | DirectX 12
(FEATURE_LEVEL_12_2)
OpenGL 4.6
Vulkan 1.3 | CUDA Compute Capability 8.9
OpenCL 2.0 | PureVideo HD ?
(VDPAU Feature Set ?)
NVDEC 5
NVENC 8 | PCIe 4.0 ×16 | GDDR6X | HDMI 2.1
DisplayPort 1.4a |
| AD103 |
| AD104 |
2022년 9월 21일에 처음 공개된 마이크로아키텍처로, 영국의 수학자이자 세계 최초의 프로그래머로 알려져 있는
에이다 러브레이스에서 따왔다. 이전까지는 성씨랑 이름 둘 중에 하나만 따온 명칭이었으나 이번에는 성씨와 이름 둘 다 있는 명칭인 것이 특징.
Hopper 마이크로아키텍처와 마찬가지로 TSMC N5의 NVIDIA 커스텀 노드인 4N으로 생산되며, 4세대 텐서 코어는 물론이고 3세대 RT 코어가 적용되었다. 가장 먼저 공개된 AD102 기준으로 면적은 이전 세대 같은 포지션의 GA102보다 소폭 감소되었음에도 공정 미세화 덕분에 트랜지스터 수는 283억 개에서 763억 개로 약
2.7배나 증가 되었다.
특이하게도 차상위 GPU인 AD103의 전체 TPC, SM 개수가 GPC 개수의
배수가 아니다. 배수가 되려면 TPC 42개, SM 84개여야 하는데, 공식 아키텍처 백서의 'Appendix B - Ada AD103 GPU Full Specifications' 섹션에 'contains 7 GPCs, 40 TPCs, 80 SMs'라고 서술되어 있기 때문.
[각주]

이 문서의 내용 중 전체 또는 일부는 다른 문서에서 가져왔습니다.
이 문서의 내용 중 전체 또는 일부는 2023-02-26 01:28:02에 나무위키
NVIDIA/데스크톱 GPU 문서에서 가져왔습니다.
 [[파일:NVIDIA 로고 가로형 화이트.svg
[[파일:NVIDIA 로고 가로형 화이트.svg










 Tesla 제품군에 대한 내용은 NVIDIA/워크스테이션 GPU 문서 참고하십시오.
Tesla 제품군에 대한 내용은 NVIDIA/워크스테이션 GPU 문서 참고하십시오.















